
Import Documents
Importing Documents into an LLM-Powered Application
This guide outlines the steps to import documents from external apps and use them in an application powered by large language models (LLMs).
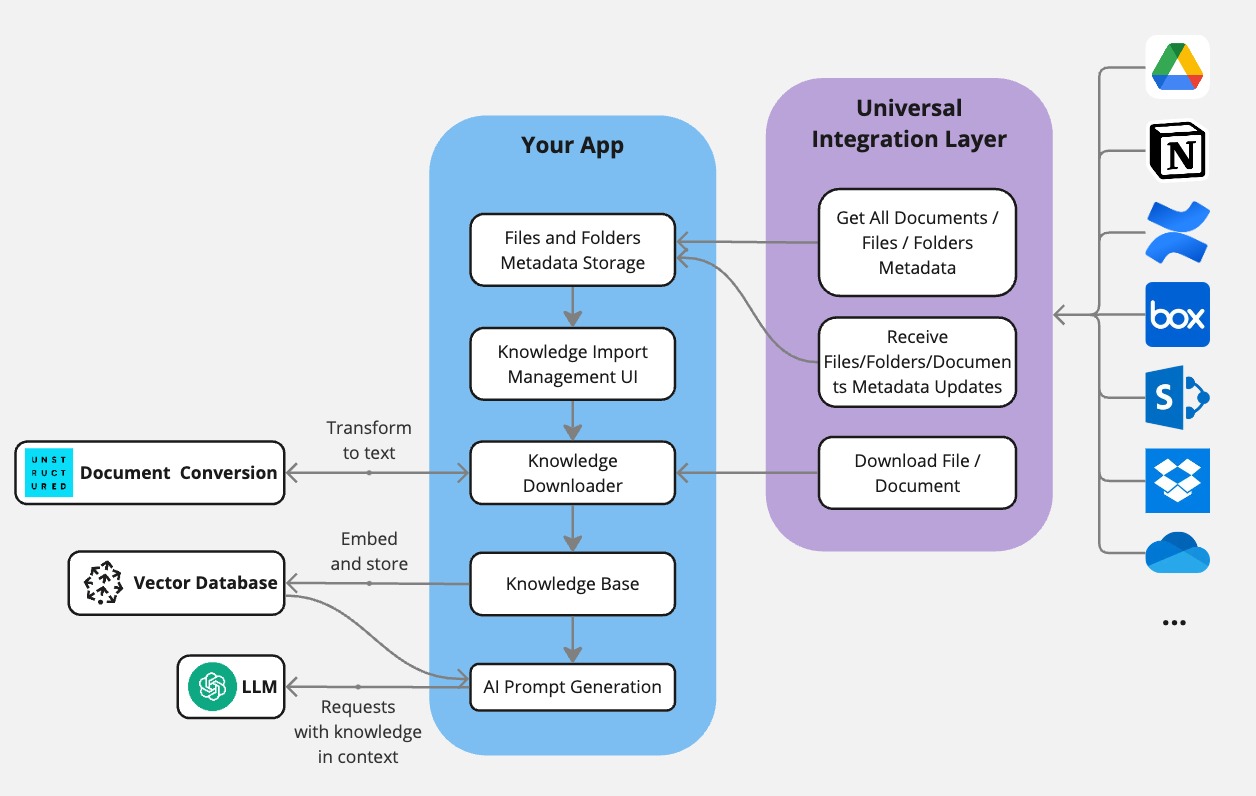
Start with a Pre-Built Scenario
It is recommended to begin with a pre-built scenario for importing documents as a starting point. You can choose a scenario that best fits your needs:
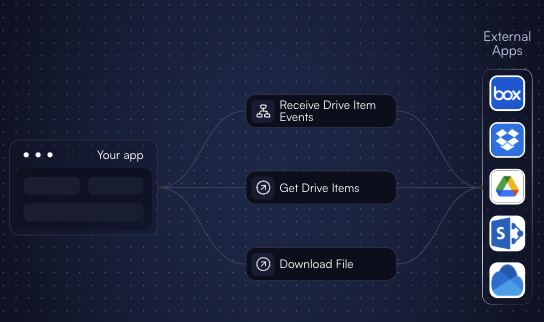
These scenarios let you:
- Get metadata about all the available files/documents in an external app, organized in folders (if supported by a given external app).
- Receive notifications about changes in metadata, such as documents or folders being added, updated, or deleted.
- Download the contents of the selected files/documents.
This lets you implement download of a full set of files/documents the user gives you access to. If you need to download only specific files/documents, read the next section.
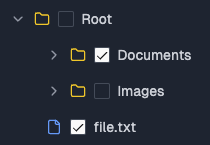
Allow User Selection of Documents (optional)
If you need to allow users to select which documents or folders of documents they want to include in the knowledge base, you can use the metadata you get from the previous step to display the list of options to the user.
You have full control over the UI, but you can use one of the pre-built examples as a reference:
- Continuous import of files displays the hierarchy of files and folders to the user and lets them download specific files.
- Coming soon... – lets users select specific folders and download all files in them.
To keep the content up to date, you should react to file change events and (re-)download affected files when they match the user's selection.
Download Files and Documents
Multiple scenarios mentioned above have a Flow for downloading files. We recommend downloading documents asynchronously to ensure the ability to handle large files without hitting limits for synchronous API requests.
For increased performance, you can initiate download of multiple documents in parallel by launching the download flow with multiple document ids in the input.
Handle Downloaded Content
Downloaded documents can be of two types:
- Text Documents: If the downloaded document contains text, proceed with further processing.
- Binary Files: If the document is a binary file, it must be converted to text. Use tools like Pandoc or Unstructured.io or other suitable methods for this transformation.
Embed Text for Further Use
The resulting text from downloaded documents should be embedded and prepared for use in Retrieval-Augmented Generation (RAG) workflows or other knowledge integration purposes.
Updated 11 days ago